Definition – Brief explanation of Web 3.0
History – Where did Web 3.0 come from?
Details – How does Web 3.0 work?
|
 |
What is it?
 Web 3.0 has had a long evolution from its first versions to its current 2.0 state, with elements of 3.0. To define web 3.0 is rather difficult as no standards have been created for it’s future evolution into 3.0. However, we can say that in general terms web 3.0 is a “semantic” web; an internet with coded information within each web page that allows for extraction of data and the correlation of that data into a form in which a computer can make sense of it all and “understand” the content. In simple terms, the semantic web allows for an understanding of what the user means to say and how elements of the content relate to each other, within and between web sites.
Web 3.0 has had a long evolution from its first versions to its current 2.0 state, with elements of 3.0. To define web 3.0 is rather difficult as no standards have been created for it’s future evolution into 3.0. However, we can say that in general terms web 3.0 is a “semantic” web; an internet with coded information within each web page that allows for extraction of data and the correlation of that data into a form in which a computer can make sense of it all and “understand” the content. In simple terms, the semantic web allows for an understanding of what the user means to say and how elements of the content relate to each other, within and between web sites.
Where did it come from?
Webvolution: Framework to Understand the transformations of the Web
Since it’s beginning, the World Wide Web (WWW) has been rapidly evolving. One framework used to understand its development is the concept of “Webvolution“, which divides the major transformations of the Web into three parts: Web 1.0, 2.0, and 3.0. The term which gave rise to this framework was “Web 2.0”, introduced in 2004 by O’Reilly and CPM Media. Although there is chronological aspect to the concept of Webvolution (Web 1.0 occurs around 1994-2004, Web 2.0 has been evolving since 2004, and Web 3.0 is in its infancy today), this framework is not a continual model. This means that the features which compose Web 1.0 exist within Web 2.0, in the same way that features of Web 1.0 and 2.0 will be present in Web 3.0. In other words, the main purpose of “Webvolution” is not to describe the history of the WWW, but to explain paradigm shifts in its transformation.
On the Beginning of the WWW
Defining exactly when the WWW starts is difficult since it depends on what point in its development one decides to consider “the beginning”. From a technological point of view, one can go as far as 1945, when “Vannevar Bush publishes and article on Atlantic Monthly describing a photo-electrical-mechanical device called a Memex for memory extension which could make and follow links between documents on a microfiche” (W3C Timeline). On the other hand, if one considers the WWW beginning, the moment when it first becomes available to the general public, 1991 still doesn’t break it. In that year Tim Berner Lee’s (creator of the WWW) paper on the WWW was only accepted as a poster session at the Hypertext 91 conference in San Antonio, Texas (W3C Timeline). The WWW finally became available to the general public in 1994 when traditional dial-up systems (CompuServe, AOL, Prodigy) started to provide access in the United States.
Web 1.0
 Web 1.0 refers to the main features of the WWW during the first 10 years its existence (1994-2004). During this time websites where information centered. Users accessed the internet in search of centralized information, which was posted by a webmaster responsible for updating content. Nobody else had the power to modify content. The user experience was limited to catalogue searching and content reading. The limitations of Web 1.0 were influenced by the early development stage of both software and hardware technology. For example, creating web-pages required programming expertise since they could only be created using HTML code. On the hardware side, bandwidth was an average of 50k, and computers processing power was significantly lower than what it was at the beginning of the Web 2.0 era.
Web 1.0 refers to the main features of the WWW during the first 10 years its existence (1994-2004). During this time websites where information centered. Users accessed the internet in search of centralized information, which was posted by a webmaster responsible for updating content. Nobody else had the power to modify content. The user experience was limited to catalogue searching and content reading. The limitations of Web 1.0 were influenced by the early development stage of both software and hardware technology. For example, creating web-pages required programming expertise since they could only be created using HTML code. On the hardware side, bandwidth was an average of 50k, and computers processing power was significantly lower than what it was at the beginning of the Web 2.0 era.
Web 2.0: Communication and collaboration
 There is no clear cut transition to Web 2.0. The Web slowly turns more interactive around the turn of the millennium. The Web evolves from a “passive” “read only” event to an “active” “read and write” “collaborative” experience. Web 2.0 is fundamentally about how user participation and collaboration has transformed and established the current shape of the web today.A critical development in the creation of an “architecture of participation” occurred in 2001 when Napster developed P2P technology. Napster “built its own network not by building a centralized song database, but by architecting a system in such a way that every downloader also became a server, and thus the network grew” (O´Reilly, What is Web 2.0). All that Napster provided was an instrument/place/context that permitted user to exchange content/data: music files. Social Networking Sites structure is fundamentally the same: they provide end users with a context in which to interact. On Ebay, users find a context where to make commercial transactions, on Youtube they find a place where to post videos, and on Flickr a place where to post pictures and create communities based on photography tastes.
There is no clear cut transition to Web 2.0. The Web slowly turns more interactive around the turn of the millennium. The Web evolves from a “passive” “read only” event to an “active” “read and write” “collaborative” experience. Web 2.0 is fundamentally about how user participation and collaboration has transformed and established the current shape of the web today.A critical development in the creation of an “architecture of participation” occurred in 2001 when Napster developed P2P technology. Napster “built its own network not by building a centralized song database, but by architecting a system in such a way that every downloader also became a server, and thus the network grew” (O´Reilly, What is Web 2.0). All that Napster provided was an instrument/place/context that permitted user to exchange content/data: music files. Social Networking Sites structure is fundamentally the same: they provide end users with a context in which to interact. On Ebay, users find a context where to make commercial transactions, on Youtube they find a place where to post videos, and on Flickr a place where to post pictures and create communities based on photography tastes.
A very interesting phenomena is the dynamic of the Web. 2.0 businesses mentioned above. The companies provide users with a service and users indirectly give value to this companies by providing content. The more content users provide the more attractive and valuable the site becomes. During Web 1.0, the value was situated in the sale of one-way information. Users would either buy access to the site or create value by generating traffic. In Web 2.0, the value lies in the content which users add into a Website. This content creates value for companies in two different ways: 1) the content attracts more users making the site more attractive, and as a result traffic is increased; and 2) the content itself represents very valuable data that the company can use for its own benefit. Google, for example, gives multiple services for free, yet it uses the information users provide through those services to compile invaluable data.
New software development technologies together with businesses´ new attitude towards the openness of programming codes (since they have realized that value lies not on selling software but on allowing users to potentialize their own platforms) have further increased the creative potential of programmers and end users. The release of API´s (Application Program Interface) by companies like Google, Craiglist, Amazon, and Flickr have permitted the creation of “mashups”: websites that tap into and combine the data of these companies to create new sources of information. For example, YouLyrics combines Youtube and ChartLyrics so that someone can watch videos with lyrics at the same time, and 2RealEstate combines Ebay and Google Maps so that all the real estate auctions on Ebay can be portrayed on a map. The combination of data to express specific information is one of the first steps of the web in the process of becoming intelligent. The potential development of the Web´s intelligence is what today is coined as Web 3.0.
Mashups are an example of how the participation of internet users has led to a “harnessing of a collective intelligence” (O´Reilly, What is Web 2.0). Three other example of how a collective intelligence is generated in Web 2.0 have to be mentioned. The first example is Wikipedia, an impressive project to tap into the knowledge of all the internet users in the world, in order to create the most extensive encyclopedia ever. Another dimension of the collective intelligence generated in the web is created through the interactions and discussions of bloggers. Technologies like RSS (Real Simple Sindication) catalyze these interactions by allowing users to select and receive up to date information on their particular interests. During Web 1.0, the web was organized by a formal taxonomy. In Web 2.0, on the other hand, users order the web according to their own criteria by using tags (the technical term for this is “folksonomy”). In Delicious, users organize their bookmarks individually by attaching tags to them, and in Flickr users do the same with the pictures they post. Metadata tags not only permit users to order things according to their own criteria, they also provide a link to unite people within a community. Once people are able to connect personally then another dimension of intelligence arises.
Back to topDetails: How does it work?
Web 3.0 Evolution
Limitations of HTML
Internet coding, starting in Web 1.0, used HTML (Hyper Text Markup Language) and was built with the sole purpose of ‘simplicity of use’ with a fixed set of tags. Hence, it had a lot of limitations and constraints under which the web-developers had to design. With the introduction of Web 2.0, a lot of plugins have been introduced, but the struggle for a more permanent solution is still on. Some of the major problems encountered while working with HTML are broken links, fixed sets of tags, formatting restraints, and inefficient search results. At the present time most search engines perform searches solely using the information displayed in the web page. This is to say that the syntax, relevance, and/or meaning of what is being searched is not taken into consideration. This basically leads to many results out of which some are relevant and some are not, and the user has to go through the pain of sifting through the results. Another problem that is faced by users nowadays is the fact that language translators do not provide accurate results. They tend to give a word to word translation instead of a context and content translation. This again is a consequence of the fact that the translator is not able to understand what the user actually means to translate.This problem basically results from the fact that HTML does not support definition tags, which would allow a designer to define the category or context of a website.
RDF – Resource Descriptive Frameworks
The steps that are being taken to address the limitations of HTML through using techniques like RDF (Resource Descriptive Frameworks) , RDFS (RDF Schema), Triples etc. These frameworks are based on making statements about the resources in the form subject-predicate-object. The resource of the web page is defined by the subject, the predicate defines attributes or traits of the subject and also defines the connection between the subject and the object. This is one of the major components of the Semantic web, and in turn enables the search of data to be much more efficient and certain.
The applications of the semantic web seem to be pervasive and endless: using a washing machine, driving, meeting, dinner booking, searching for data on the internet, meeting customer needs more effectively etc. All of these activities fall in the scope of the semantic web. The web would not only be present on a PC or some portable handheld device, but also in nearly all imaginable electronic gadgets. It would provide an endless stream of communication between all our gadgets and could proceed to manage our activities. For example, a gadget may be able to check a user´s appointments on Outlook or Facebook and provide information on available slots for a new appointments. It would also be able to link that information with travel time data and restaurant options (even according to your preferences of food and ambience) available on the web. Then it could send you options of restaurants that are on your way and that may be able to accommodate you in the time you have available. Another example: imagine that automatically, by setting your mobile phone on “meeting mode”, your status is updated on websites, your land-line goes straight to voice-mail, and your secretary receives a notification that you are not to be disturbed.
Structure

Practical Feasibility
There are major issues that need to be addressed before the semantic web can actually become a reality for the masses. Among the issues are annotation of data (how will all this data link without a central control), and artificial intelligence (a major requirement in order to process huge amounts of data). According to Zhengxiang Pan et al., the first issue is being solved by automated systems that generate semantic web data and ontology learning techniques. However, a lot of work still remains to be done in the implementation of a control system and the necessary AI to handle the large amount of semantic data that would be floating on the web.
Security: Privacy/Censorship
Some of the core issues with semantic web will stem from the fact that cast amounts of personal information will be available on the internet for grabs. This is going to lead to issues like reduced anonymity, invasion of privacy, intelligent content scraping, commoditization of information. With the increased amount of information about people available on the internet through social networking websites, personal blogs, emails, and other applications that would be connected to the semantic web, it would be rather easy to categorize people according to their income patters, preferences and social habits. This information could be used to provide user specific advertisements on pages, instead of the keyword specific ones that we see today. Also, a lot of this information can be used in the wrong way to invade on the privacy and indulge in vilifying a person in the virtual space etc. Also, with the extent of information that would be available on the internet, and the prospective natural language reading software that is expected to hit the markets, it would be relatively easy for a person to extract data, both content and context wise, from several web-pages and create articles consisting of the same information but constructed in a completely different light. This process called Intelligent Data Scraping will become increasingly automated, also making it easier for people to copy and use data from other sources without giving proper recognition to the original authors (Problems).
Considering all of the above issues, it would be imperative for the developers of the semantic web to include strong privacy and anonymity settings, which would allow users to decide the information they wish to be publicly available.
Web 3.0 components
Establishing and defining main criteria for Web 3.0 is a complex and challenging task. Although there is common agreement on the future positive implications for this next step in the evolution of the web, there is still a lot of work to be done before the Web 3.0 phase becomes a reality. In order to establish Web 3.0 it is required “to be able to define and describe the relations among data (i.e., resources) on the Web”[1].
Currently, a hyperlink is just able to create a relation between two pages. On the other hand, the semantic web is expected to create a relation between meaningful pieces of information within the web. This means the web will have the potential to interpret words and understand context similarly to humans. The semantic web is expected to store not only the content but also the meaning and the structure of a web page. In order to reach these objectives, the semantic web will utilize a different language (XML) from the one used by Web 2.0 (HTML). Web 3.0 will “go up the semantic web Language Pyramid to RDF [Lassila et al], RDFS [Brickley et al], OIL [Horrocks et al], DAML+OIL [DAML+OIL] (see above graphs)”[2].

These are richer and more sophisticated languages than HTML and should allow “semantic agents”2 to investigate the document and provide the best result for our search. RDF is a fundamental building block of the semantic web: it provides a bridge between requests and sought results: RDF “is a construct that describes the structure of the RDF vocabulary, including the terms used and their interrelationships and properties”[3]. RDF is structured as one or more “triples”:
- the subject (what the data is about)
- the property (an attribute of the subject)
- the actual value
Benefits
Consumer benefits
Customer Resource Management
- Better product and service selection (Music, Video, Shopping). Customers can obtain advantages by predictive algorithms and software that can correlate user information to offer better recommendations. Additionally, the algorithms can determine other references that can be of interest to the user, such as playing the next song on an online radio that will satisfy the users interests.
Knowledge Management
- Users can obtain improvements from semantic technology to achieve beneficial and relevant searches to their online queries. In particular, the correlation of information on the web allows more tagging of information and linking of content to provide associations of higher quality between sources and deliver improved results to user searches. Google is one company in particular that takes advantage of users past searches to predict future results.
Social Media
- Improved language translation; semantic technologies help determine the meaning in a sentence and not just the direct word translations.
- Improved links between content and cross-referencing of information.
- Creation of decentralized social networks; social networks outside specific sites like Facebook. Glue is one such widget that can aid this process.
Corporate benefits
Customer Relationship Management
- Promote cross-selling; companies can determine their clients needs to recommend other products that are similar or fall within a certain purchaser profile.
- Improved ad targeting: Peer39 matches advertisements to semantic natural language processing to increase the relevancy of the ads towards the targeted market.
- Improved ad content: Dapper is one such company that can analyze demographic, geographic, behavioural and contextual factors for improved and real-time ad content.
Knowledge Management
- Improved searching: Powerset is an example of on search engine that uses natural language processing to find better search results.
- Improved web optimization: Digger is one such company utilizing automatic tagging of information to increase the rate of correct and relevant detection.
Social Media
- Improve the reach and exposure: Headup is one service that tries to link information between Facebook, Twitter, Flikr, last.fm and other social networking sites to link together and analyze content.
- Measure the trends, tones and links between conversations; Chatmine is one company which attempts to determine the connection between community members, people and concepts.
- Determining quality of comments; blogs and other community based websites rely on user contribution, but not all of the additions are of acceptable quality. Semantic technologies could determine the relevancy and quality of contributions or material posted on the web to determine is applicability and user interest.
Limitations
Recently the US and EU government bodies decided to provide funds for[5] the development of Web 3.0; however, there are serious concerns about the feasibility of this challenging project. Tim Berners-Lee, one of the first academics to foresee the evolution of Web 2.0 into Web 3.0, in 2006 stated that “this simple idea; however, remains largely unrealized”[6]. Some of the main factors that point out to the above are censorship and privacy issues, doubling output formats, vastness of the web (more than 48 billion pages), and uncertainty. Cory Doctorow in a 2001 essay titled “Metacrap: Putting the torch to seven straw-men of the meta-utopia”, presented the first list of issues related to metadata:
- People lie
- People are lazy
- People are stupid
- Mission impossible: know thyself
- Schemas are not neutral
- Metrics influence results
- There’s more than one way to describe something
- Data may become irrelevant in time
- Data may not be updated with new insights
A more comprehensive list of problems that semantic web will face have been stated in the paper “Six Challenges for the Semantic Web”[7] which assumes that implementing Web 3.0 will require overcoming the following issues:
- Availability of the content, few pages are currently ready for the semantic web
- Ontology availability, development and evolution, given that common used ontologies must be created
- Scalability, once the semantic web is in use, it must be organized and managed in a way that can be scalable
- Multilinguality, the semantic web should overcome the language bias in order to facilitate the compilation of information posted in several languages
- Visualization, to overcome information overload, users will want to visualize the content of their research and obtain first relevant results
- Standardization of semantic web, since the effort to build its huge, a standardized effort should be made not to dissipate resources
The biggest challenge in implementing Web 3.0 will come out of human misleading behaviors, intentional or not. In fact we can imagine that the first releases of semantic web will contain a large numbers of errors due to misleading interpretation of words, most of the times set up to deceive the “semantic agents” and produce erroneous results (similarly to what occurred with first releases of search engines).
What type of solutions are offered?
Current uses for Web 3.0
Currently Web 3.0 is used with a few internet websites including iGoogle, Twine, Wolfram Alpha, LastFM, TuneGlue.net and Amazon. Most of the current business models target consumers as their main focus, but Web 3.0 is not limited to only consumer clients as both governments and businesses can also become future clients. The main uses of Web 3.0 stem from Customer Relationship Management(CRM) for personalized services along with correlating customer information to target products and services to clients of similar interests and desires. Additionally, social media websites are taking advantage of Web 3.0 to correlate users together to form network maps and user associations. Some of the most sophisticated versions of Web 3.0 aim at correlating and forming important relationships between information for improved knowledge management. Knowledge management Web 3.0 services have more powerful applications for consumers and also for businesses and governments.
Customer Relationship Management

Google stores information on past search history and success rates and then provides a personalized result based on anticipated correct matching to the users desired results.
![]()
Amazon specializes in selling products by correlating user information in order to provide similar benefits as the semantic web. Amazon understands users´ preferences by means of analyzing past transactions. In other words, Amazon matches peoples´ past purchases and profiles and recommend products the purchaser might be interested in buying. The semantic web service analyzes the information, creates smart tags and connects them to each other. The service analyzes the information not only by tags but also by users´ profiles in order to relate the information and match them together to provide personalized and relevant product matches. Amazon also currently uses Web 2.0 blogging and user reviews to help generate the content within the website. However, these characteristics are not related to what is understood to be Web 3.0 as only the suggested or “recommended” products use semantic techniques.
Example 1: Pulp Fiction
At the bottom of the search result, Amazon shows “relevant” information, recommending products that other users, who bought “Pulp Fiction”, also acquired. Amazon includes this feature in order to promote cross-selling.



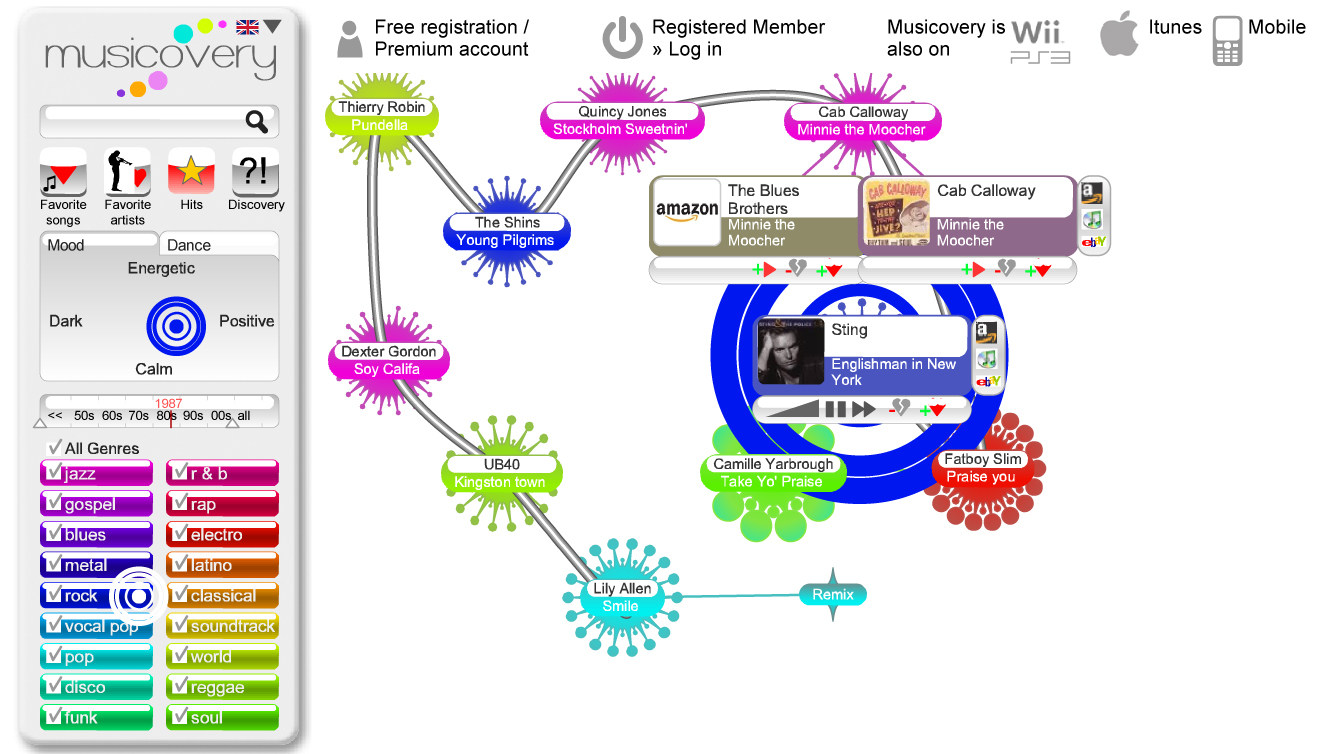
Musicovery and Last.fm both use a semantic way of mapping and correlating information together to link the music content to provide an understanding what types of music are similar and what users might like. Both websites can also use user-generated rankings to link information together, along with profile interest. The software algorithms can also tailor the information played to the user based on their own past personal preferences and also those of other users with similar musical tastes.
Example: Musicovery
Example: Last.fm
Social media


Facebook currently uses mostly Web 2.0 but has elements of Web 3.0; specifically the friend references. Facebook tries to correlate user information and create network associations in order to recommend friends that you might know. As such, it has an understanding of the users in its system and the relationships among them in order to predict future possible relationships.
Knowledge management
Twine was launched in 2007 by Radar Networks (Paul Allen, Peter Rip, Ron Conway). Twine´s advantage lies in its ability to gather many subjects/interests as objects, which then can be shared with friends. Twine links related objects by category to improve the ability to find the desired subject/interest. To draw a parallel, Facebook can be used for following what is happening with your friends while Twine can be used to follow what is happening with topics or people that interest you.
How it works:
1. Use bookmarklet to add items on the web into Twine.
2. Twine generates tags for each documents, videos, pictures and applies a semantic analysis.
3. Twine’s algorithm matches tags among related concepts, regardless of whether the information is explicitly mentioned on the web.
4. You can create a twine of any topic you’d like to track; broad or niche topics. Other users who are also interested in the topic can join the Twine, allowing the user to share and exchange information with similar-minded people.
5. If the Twine content is shared with others, the information is stored and associated with those people. If you search information, the result depends not only on the tag but also on who is searching and linked to the information. The closer the search is to the person who linked the information, the higher the rank of the result.
Twine limits the information needed to create semantic indexes by taking into account to whom and why the information is considered important,since it takes massive computing power and storage to create a semantic index. By creating the semantic indexes (in order to organize information) Twine can save time and money.


Wolfram Alphais a knowledge engine that answers factual queries, developed by Stephan Wolfram, theoretical physicist and CEO of Wolfram Research. As opposed to other search engines, Wolfram Alpha does not provide documents or lists of web pages which may contain the sought information. Instead it provides answers by means of computing relevant visual information based on structured data, and by utilizing natural language analysis and algorithms. In theory, it differs from a semantic search in that it tries to provide a single answer by creating multiple indexes of answers, however the ultimate output is similar to that obtained thru a semantic search.
Example: Natural language analysis

New projects to improve Web 3.0
THESEUS
THESEUS is a research program initiated by the German government, with the goal of developing a new Internet-based infrastructure in order to better utilize the knowledge available on the internet with the aid of semantic technologies. It also aims to make Germany and the EU more competitive globally in the information and communication areas. The main partners are SAP, Siemens and DFKI (German Research Center for Artificial Intelligence). Project members from different fields are assigned to six application scenarios and are expected to develop and test prototypes in order to find viable technological services. Below please find Theseus´six application scenarios:
- Alexandria, create platform of consumer oriented knowledge database
- Contentus, technology development of multimedia library as safeguarding cultural heritage
- Medico, scalable semantic image search on the medical domain
- Ordo, research and develop semantic technology, organizing digital technology
- Processus, optimization of business processes with semantic technology
- Texo, provide Infrastructure of business web in the internet of service
Semantic Web 3.0 and beyond
Integration with mobile phones and appliances
Web 3.0 is not appliance dependent and can be transportable on various devices. Although, the extension of Web 3.0 into mobile gadgets is not new, it might be the next direction that the version may pursue(Web 4.0). Phones are the next area that is waiting and currently being tapped for Web 3.0 exploitation. The integration of information from mobile users through GPS information will lead to future web integration for Location Based Services (LBS) and Augmented Reality.
GPS and location based services
Location based services are a software application for IP-enabled mobile devices that provide the user with geographic information. The information can be “query-based”, allowing the user to ask questions such as “Where is the nearest Corte Ingles?”. The technology can also be “push-based”, which means it can be used for marketing purposes where coupons can be sent to Location Based Service users in a specific geographic location.
LBS is defined by the international OpenGeospatial Consortium (OGC, 2005) as: “A wireless-IP service that uses geographic information to serve a mobile user. Any application service that exploits the position of a mobile terminal.”
With Web 3.0, location based services will provide much more interactive applications such as the “social compass”, allowing the user to identify friends in the vicinity.
Another social application that LBS will allow for in combination with Web 3.0, is that of micro-blogging. This application embeds the user´s geographic location to their blogging. Such will be the case with “geo-tweets”, which Twitter is expected to launch very soon.
In a research done last year by ABI Research, location based social networking is expected to become a $3.3 billion market by 2013.
Augmented Reality
Augmented Reality (AR) is a technology that combines digital data with real world images, in real-time. As Google´s Enkin for Android defines: “It displays location-based content in a unique way that bridges the gap between reality and classic map-like representations. It combines GPS, orientation sensors, 3D graphics, live video, several web services, and a novel user interface into an intuitive and light navigation system for mobile devices.” (Enkin)
In use with Web 3.0., AR will provide for a much more interactive interface, where the mouse can be your hand and the browser your own clothes. Augmented Reality will also allow for GPS based applications to better determine the precise location of the mobile device and superimpose the information with virtual data. Therefore, by using GPS information, the semantic web can analyze where you are at a particular moment and understand your location in order to provide valuable and desired information.
There are currently Augmented Reality applications for mobile devices, such as for Apple´s iPhone.
Future evolution of the format
No one knows for certain how Web 3.0 will evolve, but it is known that it is becoming more integrated with mobile and non-PC computer devices. Until the next paradigm shift we can be left wondering what will be the next version, into Web 4.0, but we know it will become more knowledgeable and intelligent. With more computer and processing power, servers may be able to predict and service users before a demand even arises, in a predictive format; though this is only a guess and science fiction is full of other wonderful and enigmatic scenarios.
Additional sources:
[1] “What are the major building blocks of the Semantic Web”
[2]Six Challenges for the Semantic Web, V. Richard Benjamins, Jesús Contreras, Oscar Corcho and Asunción Gómez-Pérez
[3] “What are the major building blocks of the Semantic Web”
[4]“Definition of RDF”, PC Magazine
[5] Six Challenges for the Semantic Web, V. Richard Benjamins, Jesús Contreras, Oscar Corcho and Asunción Gómez-Pérez
[6] Nigel Shadbolt, Wendy Hall, Tim Berners-Lee (2006). “The Semantic Web Revisited”. IEEE Intelligent Systems
[7] Six Challenges for the Semantic Web, V. Richard Benjamins, Jesús Contreras, Oscar Corcho and Asunción Gómez-Pérez
The Semantic Web, Frequently Asked Questions (W3C)
The Evolution Of Web 3.0, Slide Show
Evolution Web 1.0, Web 2.0 to Web 3.0, YouTube
3WC, Timeline of Evolution of WWW
{kind=link}
{kind=link}
Links for your knowledge:
Paper on Semantic web from Scientific America and founding thinker on the issue
Thx. It was indeed well worth the read.